

Have you ever thought that your AI has the capabilities of thinking and remembering?
You ask ChatGPT or Gemini a question, and it replies intelligently, but it is not up-to-date.
Or you take hours feeding your chatbot documents, and then 5 minutes later, it forgets all.
That is the issue; in traditional AI models, there is no knowledge of something new. They utilize stagnant training data.
However, what would it be to have your AI be able to access the most recent data, comprehend your own situation, and create answers that are accurate and relevant at the same time?
RAG AI (Retrieval Augmented Generation) does precisely that. That is why modern artificial intelligence (AI) applications such as ChatGPT, Perplexity, or enterprise copilots remain accurate, dependable, and up-to-date.
We will discuss how you may deploy RAG AI to streamline workflows, maximize productivity, and create smarter systems without lifting the heavy load.
Why Are AI Enthusiasts Still Intrigued by RAG?
Because RAG is the missing link between human and machine intelligence.
Although Large Language Models (LLMs) such as GPT-4 or Claude are hard to deny their power, they have limitations; they cannot retrieve real-time information or enterprise-specific knowledge unless they have some form of external connection.
RAG bridges that gap.
It is similar to having your AI personal Google search engine + personal memory vault, which will provide facts, documents, and immediate context before replying.
How It Got Named “RAG”?
The technique known as RAG Retrieval-Augmented Generation, like most other AI innovations, was not created due to the marketing department.
The term was first introduced in a 2020 research effort of Patrick Lewis and his team at Facebook AI Research, who were testing how to alter large language models to be more factual and less hallucinatory.
Interestingly, Lewis has stated that the name “RAG” did not have to sound catchy; it was simply a good fit.
The model would extract knowledge from the external sources, enrich its internal knowledge, and then extract an output. Basic, factual, and technical, although not even glamorous then.
When looking back, Lewis acknowledged that they could have made a better choice, as they would have understood how popular the idea would become. What started as one of the abbreviations of the term research gradually evolved to a fundamental paradigm that runs the latest and most modern AI utilities, from enterprise search bots to the upcoming generation of LLM applications.
“If we’d known the name would stick across the entire AI industry, we probably would’ve brainstormed a few more options,” Lewis joked in a subsequent interview.
However, the name proved to be appropriate.
Retrieval-Augmented Generation does all three named things, i.e., it retrieves, augments, and generates, meaning that it endows unstable and often language-scale models with access to real-time, credible information, coherent, and human-like response generation.
What is RAG AI (Retrieval-Augmented Generation)?
Think of the situation when you provide your AI with both its own knowledge and your personal library.
That is what RAG AI is all about: Retrieval-Augmented Generation.
To put it simply, RAG AI is a combination of two processes:
- Retrieval: The AI scans a linked body of knowledge (such as PDFs, websites, or databases) to find out the information that is most relevant.
- Generation: It then applies that recovered information into crafting correct context-sensitive responses.
RAG AI then checks things up and gives an answer rather than guessing the answer.
That is why RAG is then actively used in tools such as Perplexity AI or enterprise copilots under the hood, to ensure their response remains factual, up-to-date, and reliable.
Why RAG AI Matters?
Older Large Language Models (LLMs) such as GPT-4 or Claude are robust, but have reached an endpoint on the data that they have been trained on – in other words, they are unable to access new and private information.
That becomes an issue with real-time facts, company-specific responses, or insights being compliant and safe.
It is here that RAG AI comes in:
- Accuracy: It does a cross-check of facts, then it generates responses.
- Information Self-Governance: You control what information it retrieves, such as maintaining the safety of sensitive files.
- Scales at Cost: There is no need to retrain or optimize the model each time your data changes.
- Domain-Specific Intelligence: It is responsive to your business terms, reports, and style.
- Trust & Transparency: It is even citable as a source of information.
Want to create your next-generation AI solution? Sketch your custom RAG AI workflow.
How RAG AI Works?

Imagine RAG to be a two-brain system:
- One brain searches (retriever).
- The other writes (generator)
These two are closely connected in a feedback mechanism so that every response is relevant and reliable.
Steps in the RAG Process
Create and Ingest External Data
The first thing is to grab your content PDFs, articles, spreadsheets, databases, or transcripts. This information is then translated into embeddings (meaning numerical vectors). The embeddings are inserted into some kind of vector database like Pinecone, Weaviate, or FAISS.
Retrieve Relevant Information
On entering one query, the retriever searches the database and identifies the most appropriate pieces of text, which are usually referred to as the chunk. These fragments are facts to which the AI can get access.
Augment LLM Prompts
A chunk that has been additionally fetched after this is fed into the technology so the LLM can view nutritious and contextual information, after which it responds. This is the act in which there is a convergence between retrieval and generation.
Generate Contextual Responses
The writing of a human-like response to the facts retrieved is now done levelly by the LLM (as well as GPT-4 or Claude, or Mistral). It resembles the research conducted by human beings when explaining something.
Update and Maintain Knowledge Sources
You update the knowledge base on a regular basis to maintain high levels of accuracy.
Redundant documents are rewritten, old ones updated, so that the AI will forever lead to updated information.
In short:
RAG AI = Retrieve first, generate second.
The mere addition of that intelligence will make your AI smarter, faster, and much more reliable, just what modern workflows require.
Core Components of a RAG System

To determine how RAG AI really functions, we will deconstruct its four building blocks.
Imagine them as the organs of your AI system; each of them is of key importance in the way information circulates and answers are given.
Knowledge Base
This is the brain storehouse. This is where all your information is.
It may also contain documents, emails, product manuals, research papers, or even API data.
They are turned into embeddings (mathematical formulations of meaning), and they are stored in a vector database like:
- Pinecone
- Weaviate
- Milvus
- FAISS
The more thorough your knowledge base, the smarter your RAG system.
One significant finding of an IBM report published in 2024 revealed that reaction to context was observed to be up to 70 percent more relevant in RAG models with organized knowledge presumptions than those executed by models that were trained with overt datasets only.
Retriever
The trusty assists you in thinking that a search engine within your own AIs is what the retriever is.
You ask a question, which in turn searches the knowledge base in search of the most appropriate information chunks, such as web pages being ranked on Google.
Retrievers can use:
- Understanding meaning is referred to as semantic search.
- Exact matches Keyword search
- Hybrid search (a mix of both)
An appropriately tuned retriever will make sure that your AI always begins with the most contextually relevant information, then creates an answer.
Integration Layer
This forms the connection between the retriever and the generator. It deals with the packaging of the results retrieved and feeding them into the language model.
The integration layer is also able to handle:
- Metadata screening (e.g., data only on trusted sources)
- Timely processing (inputting gained information into the LLM prompt)
- Reranking/ scoring (selecting the best snippets to forward)
Search and synthesis are facilitated through the middleman to get smooth and meaningful communication.
Generator
Lastly, the generator typically is an LLM (Large Language Model) like GPT-4, Claude, Gemini, or Mistral that processes all the information found and develops a natural and human response.
Here, retrieval comes into conflict with creativity.
The generator does not just spit out the data back to you again and again, but it makes sense, summarizes, and contextualizes it to your query. This is why RAG systems are so intuitive; they blend the accuracy of search with the fluency of language generation.
Automate your business to the next level. Hire our AI Developer to make your intelligent systems a reality with our experienced team.
Standard vs Advanced RAG Workflows
Having discussed the basic building blocks, it is time to dive into the understanding of how RAG AI processes can be transformed from a simple configuration to an advanced, production-scale architecture.
Standard RAG Methodology
The conventional model has a simple 3-phase cycle:
- Retrieve: and get information that is relevant to your vector database.
- Augment: Add such information to the prompt.
- Generate: Be creative with the LLM.
It is best suitable for small projects, in and within company bots, or when prototyping.
Nevertheless, workflow customization goes further with RAG when it is necessary to operate on an enterprise scale and minimize latency.
Advanced RAG Techniques

Chunking & Vectorization
Documents are divided into smaller textual fragments (such as paragraphs). The chunks are transformed into each as a vector embedding, enhancing search accuracy and recall. Dynamic chunking is used to remember context in a non-exceeding number of tokens.
Search Indexing
Embeddings are also indexed so that it is easy to look them up. HNSW (Hierarchical Navigable Small World) graphs or Approximate Nearest Neighbor (ANN) search apply to modern systems to process millions of data points at high speed.
Reranking & Filtering
Results produced by a retrieval are reranked using psychoanalysis instruments like Cross-Encoders or FlagEmbedding so that the most relevant chunks are shown first. You may also use filters, such as; filter to responses to data after 2025 only.
Query Transformations
There are occasions when users make queries in a bad manner. Response transformation rewrites their query or broadens their query into several optimizations of the query they have (multi-query rewriting) to further the recall.
Example: “AI in healthcare” or “What is AI doing to streamline the work of a hospital? or “Medical diagnosis by machine learning”.
Chat Engine
The chat engine also uses multi-turn conversation management, and it remembers the context, does follow-ups, and continuation between questions. It makes RAG not a one-time question and answer application but an actual conversational helper.
Query Routing
When you need more than one source of data (e.g., in HR documents, product manuals, and marketing files), the query routing will automatically send each query to the most appropriate source. This has weakened the sensitivity to noise and also enhanced the precision of the response.
RAG Agents
The best RAG systems employ agentic processes, the domain specialist being performed by the specialized retrievers or agents, e.g., legal data, analytics. Agents work together to construct multi-layered and expert-level answers.
Response Synthesizer
The response synthesizer synthesizes multiple snippets after they are brought into memory and processed together into a unitary and perfectly logical message, making them clear and logical.
A Hugging Face benchmark (as of 2025) found that hybrid RAG systems based on reranking and multi-query transformation outperformed standard RAG on the accuracy of responses by 28 per cent.
In short:
- Standard RAG = Think back and React.
- Advanced RAG = Retrieval, Reranking, Reframing, and Refining.
The raised evolution makes RAG AI not a simple engine of retrieval but a context-oriented, intelligent reasoning system that will be able to assist real business operations in the context of business with accuracy, fast, and reliability.
Grow at a faster rate using Intelligent Software Solutions crafted to automate processes, improve accuracy, and lead to concrete growth.
Fine-Tuning and Optimization in RAG AI
Although RAG AI is a good representation of any AI, it does not function excellently with all datasets and domain types by default.
It is where fine-tuning and optimization are in place.
Fine-tuning assists your AI to identify you and your particular data type, comprehend your sector, secure reasonably information smarter, and answers will be clearer, quicker, and also more significant.
We can divide this into the four essential components of RAG optimization.
Encoder Fine-Tuning
The encoder does the work of text-to-embedding-fingerprint, which can hold meaning. When the accuracy of these embeddings is not high, the retriever will be unable to retrieve anything.
The fine-tuning language lets your AI get more familiar with your language, be it legal or medical names, or a document.
For example:
The RAG model of a hospital can be tweaked to ensure that MI, which translates to myocardial infarction (heart attack), and not Michigan, is identified. One real estate RAG system solves the problem that a plot file does not mean computer data; it is the name of the property document.
A study of fine-tuned encoder retrieval by the Stanford AI Laboratory in 2024 showed that there was an increase of 27% in retrieval accuracy compared to using generic sentence-transformer encoders.
Ranker Fine-Tuning
No document is always useful, even with the retrieval. This is why ranker fine-tuning does.
The Ranker model will put the retrieved chunks in order so that the most useful ones are displayed at the top of the list, similar to the ranking of search results provided by Google.
Using fine-tuning, the ranker gets to know what your users appreciate:
- Whichever applies to customer care bots, emphasize FAQs or troubleshooter manuals.
- In the case of research assistants, research academic citations or verified reports are to be prioritized.
This step assists in noise rejection, clarifying the context, and enhancing factual consistency and convergence when the generator has not yet written even a single word.
LLM Fine-Tuning
The voice that is attributed to your RAG system is the Large Language Model (LLM) itself, which processes the information that is retrieved and composes the final answer. The retriever will deal with what to say, whereas the LLM will deal with how to say it.
Fine-tuning the LLM helps it:
- Use the tone or brand voice of your company.
- Be better with particular instructions.
- Give the correct degree of technical response.
- Stay on track (e.g., legal disclaimers or medical accuracy)
Particularly in business settings, the pursuit of consistency, controlled language, and controlled communication, especially in terms of the brand, values fine-tuned LLMs.
In scientific research, domain-tuned LLMs emerged in surveys by OpenAI, 2024 than other raw text-starring models and have been demonstrated to achieve increased fact matching by 31% and decreased off-topic results by 42% (Enterprise Data Study).
Evaluation
Lastly, even the finest RAG pipeline requires evaluation.
Why? Since your data is dynamic, the requirements of the users change.
Consideration in RAG AI normally addresses:
- Precision: Can the answers be said to be true?
- Recall: Is the retriever pulling the right chunks?
- Latency: What is the response rate of the system?
- User Feedback: Do the users find user satisfaction in terms of tone and richness?
Enhanced configurations perceive the use of human-in-the-loop testing and automated statistics, such as BLEU, ROUGE, or Recall k, as a system to gauge performance as it occurs.
One does not only want to be correct at one point in time, but at every point, as your data increases, so as your accuracy.
RAG Optimization Strategies
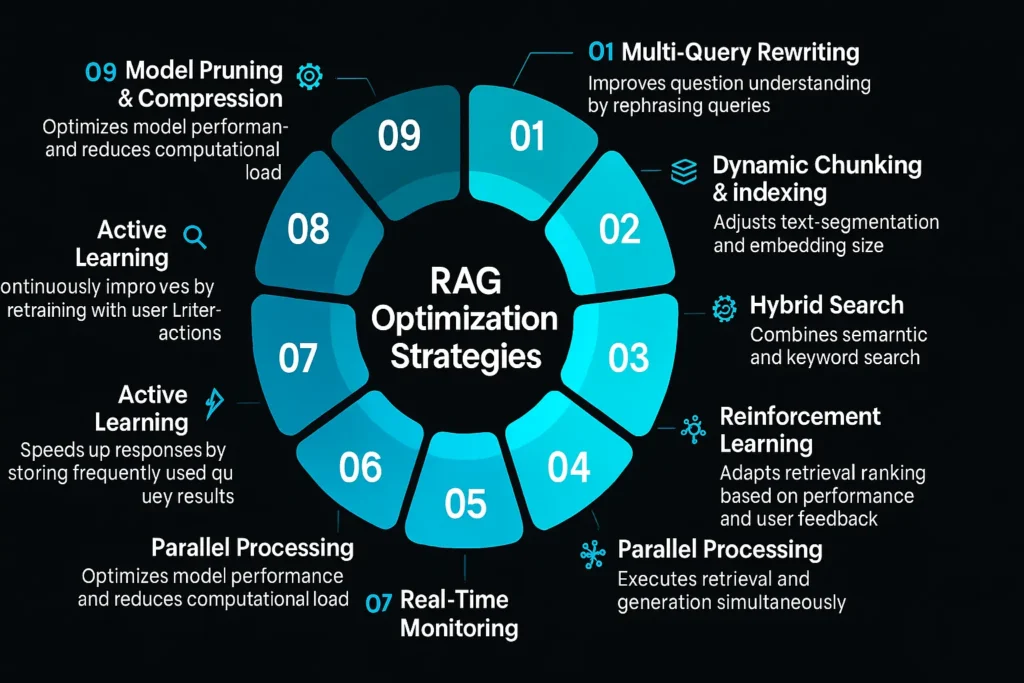
It is fun to build a RAG AI system, but the magic to activate at scale lies herein.
RAG workflow with a high level of optimization can provide faster reactions, shortened hallucinations, and can remain stable up to the moment when your information is measured in millions of records.
We are going to dive into ten effective, research-supported methods that the top AI teams are streamlining RAG pipelines to achieve high speed, precision, and ensure the cost efficiency of the processes.
Multi-Query Rewriting
The majority of users do not use perfect questions; they type carelessly or vaguely. Multi-query rewriting assists your RAG system in addressing this through the generation of multiple forms of the same query.
For example, if a user asks:
- “What could RAG AI do to assist us in business processes?”
It could also be modeled in search of:
- “Benefits of retrieval-augmented generation in automation”.
- “RAG examples of making things happen to increase productivity”.
All the rewritten queries are considered to have an alternative angle.
The retriever then compiles the results of everybody and combines them to produce a more comprehensive picture.
This minimizes precious information lost in context and results in a huge boost in the quality of recall.
Google DeepMind reports that up to 33 percent in factual recall in RAG systems and a decreased rate of hallucinations were possible with multi-query rewriting (5).
Worth noting: Processes such as T5-QueryRewriter or gpt-4o-mini of OpenAI can be used to generate a variety of intent-conscious query rewrites.
Dynamic Chunking & Indexing
The whole process of dividing your documents is called chunking before you elaborate on them.
Pieced together with content structure and type as opposed to the one-size-fits-all approach, dynamic chunking adjusts itself to its incorporated content.
- In case of large policy documents, bigger chunks, remember context.
- In the case of ratios in smaller sizes, precision is captured.
These samples are embedded (encoded into vectors) and put into a vector index such that the similarity search may be performed quickly.
Then, dynamic indexing is used to enable quick and scalable access to such embeddings with algorithms such as HNSW or IVF Flat.
The outcome there is an improved speed of retrieval and more accurate context, since your chunks are completely tuned toward the meaning and query intent.
In the case of RAG models, an Intelligent Assistance via AI Systems Report (2025) established that production-scale trial-size AI is able to save 41 seconds on retrieval time through the use of adaptive chunking and mixed indexing.
Hybrid Search
Hybrid search combines two searching approaches:
- Lexical search (keyword searching)
- Semantic searching (based on search meaning)
Combining the two, you not only capture queries that semantic models may overlook (such as names, codes, or numeric data), but also the queries tend to detect connections between two independent queries.
Example:
The medical RAG system that tries to find “HbA1c” with a keyword search will fail to match it semantically, whereas a keyword search will match it at once.
With a combination of both, word precision, along with understanding, is guaranteed.
BM25 is used in hybrid systems as a ranking with respect to keywords, and semantic recall is done with the help of vector similarity.
This bilateral methodology has become common with AI pipelines that have enterprise requirements.
The 2025 AI Infrastructure Study conducted by Gartner revealed that semantic-only systems gave a reduction of 38% in answer precision with using hybrid RAG retrieval.
Reinforcement Learning
Reinforcement Learning (RL) is the engine of continuous improvement of your RAG that you should think of.
As time goes by, your model improves the status of user reports. Was this helpful? “Was this accurate?” modifies recall behavior.
Here’s how it works:
- Good responses: Positive reward-like responses are prioritized.
- Poor responses: Negative reward, disincentive plan restructured.
This self-feedback process is useful in keeping the system dynamic; no fine-tuning of the system is needed.
A variety of other scenarios (such as reranking, query routing, and context weighting) may also be brought to RW and made self-adaptive with RAG.
In 2025, OpenAI and Meta co-reported results of higher long-term reliability of RAG systems with RL feedback, which can be increased by a factor of 45 percent.
Example: Customer service robots that are adaptable to understand what articles provide the quickest solution to problems over time.
Prompt Compression
RAG models tend to work with long pieces of text in input- large enough to overflow the token window of your LLM. This can be solved immediately through compression, which summarizes or telescopes retrieved text and sends it into the model.
It is not simply redundancy truncation, but it is cleverly doing so without loss of meaning. A summarization model or embedding-based filtering can help to select only the most relevant content.
This helps in three ways:
- Reduced latency (reduction in input = reduced response time)
- Lowered price (Fewer tokens expended).
- More focus (less noise in the picture)
Parallel Processing
The vast majority of RAG pipelines sequentially retrieve and process documents.
Parallel processing modifications that divide tasks into several processing units through many threads, or Graphics cards.
For instance:
- A single thread retrieves the best documentation.
- Another summarizes them.
- One of them prepares the context for the generator.
All this is done concurrently and reduces the response time to a very minimal amount.
This is particularly helpful in the case oforerator is a chat-based RAG assistant with thousands of individuals.
The RAG Optimization Study by NVIDIA achieved a 3.2x parallel-retrieval and parallel-generation pipeline throughput.
Tools to investigate: Multi-threaded chain of LangChain or Ray, or Dask, when it is necessary to search during high throughput.
Active Learning
Even an optimum retrieval model must be constantly improved.
Active learning shifts the retraining attention towards low-confidence responses or uncertain responses.
Here’s how it works:
- Uncertain answers or low confidence retrieval are identified in the system.
- They are rectified by human reviewers.
- Such instances furnish high-value training data in the subsequent round.
That is why you would have a RAG that keeps to its weakest point, continuing to improve.
It is a fast method to create a self-enhancing retriever as time goes by.
The Active Learning Study by Meta AI (2024) showed that this method corrects the retrieval by 30% merely with 10% of all data that was manually labeled.
Caching & Pre-Fetching
Probably the most powerful, but also least demanding, optimization is caching.
Many frequently asked questions and their answers are stored in the memory or disk, which can be recalled at any time to be answered instantly.
Meanwhile, pre-fetching also guesses the next query that a user may make and then prepares it beforehand.
Example:
When asked to define what RAG AI is, the system may get this pre-fetched:
- “How does RAG AI work?”
- “What are RAG AI benefits?”
Caching combined with pre-fetching may also reduce the latency of popular queries by a factor of 70-90.
Model Pruning & Compression
Big models are active but usually excessive.
Redundant parameters are eliminated during a pruning process, and the model size can be reduced by a compression algorithm, such as a quantization algorithm.
This reduces:
- Memory consumption
- Energy usage
- Compute cost
It provides faster inference, in particular, when running on-premise or at the edge.
After combining this with retrieval efficiency, pruning would make your RAG AI lightweight and scalable.
Real-Time Monitoring
The process of optimization is not a one-time task. Monitoring helps you to keep an eye on the health and performance of your RAG pipeline on a real-time basis.
You can monitor:
- Retrieval accuracy (Recall@k)
- Latency per query
- User satisfaction metrics
- Freshness of data sources(update of data)
You can automatically rectify anomalies when you notice them, such as decreased speed of retrieval or hacked data.
This also makes your RAG system consistent as your dataset and user base continue to grow.
Suggested tools: LangSmith, Arize AI, or Prometheus dashboards for trying to get the latency of retrieval and generation.
Change the way your AI communicates. Hire our Prompt Engineer who best designs accurate prompts that improve model effectiveness and external accuracy.
Building Your Own RAG Workflow
It is not an uphill task to create a RAG AI workflow when you divide it into straightforward procedures. The following is how to get raw data to credible retrieval-augmented intelligence.
Step-by-Step Process
Preparation
- Set objectives: Determine whether you are creating a chatbot, research assistant, or analytics.
- Select stack: Select an LLM (GPT-4 and Claude as well as Mistral), a vector database (Pinecone, Weaviate, and Milvus) system, and an orchestration system (LangChain and LlamaIndex).
- Plan data flow/find information to index: Determine what to index and the frequency of updating it.
- Add security: Inclusion of access roles, encryption, and logging.
- Record all: Purpose, KPIs, and compliance boundaries.
Ingestion
- Gather information: PDFs, documents, web reviews, tickets, and databases.
- Clean it: Delete duplicates/ advertisements/heads.
- Chunk and embed: When models such as text-embedding-3-large are used to convert text to embeddings, it is recommended to divide it into 2000-400-token chunks and then turn them into embeddings.
- Store MySQL: Add metadata (author, metadata, date) and index your database expression(s).
- Version control: Version hash files to update only the changed text.
Retrieval
- Auto-correct queries: Spelling, intent, and improve abbreviations.
- Hybrid search: Keyword (BM25) search + semantic vector search.
- Filters: Inclusive or exclusive by date, source, or access level.
- Rerank: The top successful encoders are the ones that are reordered in order of relevance.
- Confidential scoring: In the event of low levels of recall, proceed by clarifying queries or marking no answer.
Generation
- Immediate construction: This occurs by a combination of user query + bestseller chunks, + clear instructions.
- Immediate compression: Constricted context to avoid exceeding the number of tokens.
- Semantic statements: including an overview, facts, and referrals.
- After-processing: Get rid of duplicate content, censor sensitive content, and connect to sources.
Optimization
- Cache: Cache common queries so that they will be immediate.
- Pre-fetch: Predictive next questions to minimize goodswat.
- Parallelism: Recall, summarize, and produce, at the same time.
- Active learning: Feedback: Retrain the retriever.
- Dynamic k: Determine that fewer chunks are needed in campaigns with high confidence to reduce the cost.
- Observability: Determinism, Track Recall, latency, and user satisfaction.
Challenges and How to Tackle Them
Data Structuring
Disorganized data reduces the retrievability.
Normalize formats, label metadata data, and employ powerful parsers using OCR.
Incremental Updates
Indexes must stay fresh.
Resort to hashing, re-embedding on schedule, and blue-green index swaps.
Managing Inaccuracies
AI can also make hallucinations or draw obsolete information.
Show citation only prompts, put recent data to the front, and include fallback responses as “ I don’t know” responses.
Cost & Scalability
The tokening and computation costs may increase rapidly.
Use compressed prompts, have smaller models when making simple queries, and have aggressive caches and autoscaling.
Design intelligent, rapid, and efficient systems. Hire our AI Engineer to develop, implement, and optimize your future smart AI-based apps.
RAG AI Use Cases and Industry Applications
RAG AI is changing team behaviours in terms of work, learning, and communication. Space: Making retrieval (finding facts) and generation (writing answers), it can be applied to almost any business activity and industry.
Let’s find out the most insightful use cases, as well as practical applications.
Specialized Chatbots & Virtual Assistants
RAG chatbots do not use guesswork, but before returning an answer, they access known company information. They deal with frequently asked questions, HR manuals, employee orientation handbooks, and product-related literature carefully.
Example: A chatbot legal firm that uses case law or several clauses from uploaded contracts.
Research & Knowledge Management
RAG AI does not require one to skim through countless PDFs or notes to find the related passages, but can do so in a couple of seconds. It is as though you had a personal researcher who reads your entire database at the request of the researcher.
Example: RAG is applied by scientists to Camscan 10,000 + papers and summarizes the most recent results automatically.
Content Generation & Summarization
RAG AI enables marketers, writers, and analysts to make the content they build based on factual aspects and not hallucinated text. It is capable of summarizing long-term reports, building outlines of blog posts, or reusing brand-related documents.
Example: Within a news agency, RAG can serve to create brief ARs based on verified feeds daily.
Market Analysis & Product Development
RAG systems assist firms in monitoring competitors, consumer trends, and product insights with the help of internal and external data. They connect organized and unorganized sources, uncovering information that is actionable.
Example: A retail brand further simplifies the summarization of their customer reviews, survey results, as well as competitor reports via RAG in a single dashboard.
Customer Support Automation
The RAG-powered assistants can minimize the number of support tickets because they can find correct answers in manuals, FAQs, and chat histories. They deliver similarity to brand interaction over time as they acquire experience through genuine customer experiences.
Example: A telecommunication company reduced response time by 60 per cent after replacing chat support, which had been managed using RAG, with help from engineers on RAG-powered support chat.
Enterprise Knowledge Engines
Large organizations rely on RAG to integrate siloed stores of knowledge, single to shine, be it Notion, Confluence, SharePoint, or CRM. Employees receive direct yet precise answers, as opposed to accessing folders.
Example: A Multinational employs RAG as an internal brain or company brain that retrieves real-time project updates and policies throughout their departments.
Healthcare
RAG used in the healthcare sector has helped medical specialists and other stakeholders to retrieve recent medical literature and patient information easily and without threats. It does provide contextualized suggestions that do not assume the role of the medical judgment.
Example: An assistant of a hospital RAG suggests the appropriate treatment procedures, depending on the signs of a patient and the recent research articles.
Finance
RAG AI helps banks and fintech companies to summarize financial reports, compliance policies, and policy documents. It gives precise data on client advisory, fraud detection, and market monitoring.
Example: The chatbot of an investment consultant relies on RAG, which uses verified information on SEC filings and everyday market data.
Manufacturing
RAG AI streamlines the production process and maintenance performance since it retrieves guides on equipment, sensor records, and safety provisions.
Example: RAG chat assistants are used on the factory floor by engineers to fix problems in real-time through documentation of machines.
Education & Research
Teachers rely on RAG to deliver learning content based on individual learners, produce lesson summaries, or plan course content. The advantages of using sourced insights lie with researchers using the findings of thousands of scholarly articles and more.
Example: A university finds the application of RAG, which allows students to chat with the lecture notes, research archives, or the e-libraries.
RAG AI vs Fine-Tuning

Develop your personalized artificial intelligence solutions to organize and process data, learn, and act on ideas. Build the future with us.
Contact Us!
Best Practices for RAG Optimization
Developing a reliable, scalable, and ethical RAG AI system is one thing, and maintaining it is the other.
The following five best practices are certain to keep your RAG AI workflow accurate, efficient, and trustworthy in the long term.
Smart Document Ingestion
Begin with well-organized data that is clean. Duplicated or poorly formatted documents bring about low quality of retrieval.
Best practice:
- Divide it into semantic pieces (divided by a heading when splitting).
- Provide metadata such as title, author, and the date of publication.
- Filter the old files or the poor quality ones.
- Automate API ingestion or updates.
Multi-Representation Indexing
The use of one type of indexing should not be counted on. Multi-representation indexing keeps the text data, tables, and visual data in various forms to ensure that all knowledge types are retrieved.
Best Practice:
- Linear up (hybrid indexes BM25 + vector embeddings).
- Insert interrogated metadata of filters.
- Supports image-to-text or table extensions to non-text data.
This is necessary to make your RAG system cognizant of words, digits, and images rather than sentences.
Feedback Integration
A great RAG system is user-aware. Gathering and implementing feedback helps in shortening the longevity in retrieval.
Best practice:
- Thumbs-up/ down or satisfaction scoring.
- Bad or poor confidence queries.
- This real-world feedback should be used to retrain the retriever or ranker.
This generates a process of active learning, assisting your RAG AI to advance perpetually.
Ethical AI Implementation
Being transparent, respecting the privacy of data, and being bias-preventative are not merely a luxury. Users need to be aware of the origin of responses of an AI and what data it is processing.
Adhere to ethics-first by practicing the following matters:
- They should be sourced when responding.
- Do not use personal or sensitive information.
- Make sure that the retrieval logs are audited on a regular basis to verify the possibility of bias or misinformation.
- Adhere to the workflows and GDPR or HIPAA standards or local standards.
Expert Collaboration
The AI, even the most effective one, requires the human touch. Work with field specialists (researchers, engineers, analysts) to test your data and worse.
Best practice:
- Label or check several responses by experts.
- Apply their observations to improve the rules of chunking or the filters of retrieval.
- Provoke data sustainers and content owners to interact as cross-team members when it comes to feedback.
This makes sure that your RAG AI does not sound right; it is right.
How EXRWebflow Supports RAG AI Implementation?
We work in the sphere of designing end-to-end RAG AI workflow with modern businesses at EXRWebflow.
Our solutions enable the teams to make scalability between a prototype and an AI system that is production-ready, safely, efficiently, and at a low cost.
Here’s what we offer:
- Your own RAG Pipelines; built for you.
- Database Integrations: Pinecone and Weaviate.
- RAG-Powered Chatbots: That cite a verifiable source of the company.
- Fine-tuning and analytics: To continue improving the performance daily.
- Data Security/Compliance: Securing your intellectual property all the way.
Get intelligent, context-aware artificial intelligence with EXRWebflow to develop an intelligent AI ecosystem that makes your data smarter about you.
Conclusion
RAG AI is transforming the domain of construction and the utilization of artificial intelligence.
By integrating facts when seeking the truth and language when generating, it closes the links between what comes out of raw data and intelligence in making decisions.
RAG, when properly optimized based on good data, ethical structure, and human understanding, is more than another mathematics model: it engages in life and grows with your organization.
It is the future of AI that is going to be understanding, citing, and evolving.
Frequently Asked Questions (FAQs)
What is RAG AI used for?
To create systems that can access verified information and provide correct and contextual responses, the implementation of RAG AI is employed, which is ideal in chatbots, research aids, and knowledge assistants of an enterprise.
How is RAG different from an LLM?
LLMs rely on pre-trained data. RAG AI links them to live or personal data streams, such that they provide factual responses.
Is RAG better than fine-tuning?
The flexibility and freshness with which RAG is better are the highly specific task or the highly stylistic task for which fine-tuning is better. Numerous systems combine the two.
What industries can benefit from RAG?
Healthcare, finance, education, manufacturing, and customer care, or any area that requires credible, modernized knowledge, can benefit from RAG AI
How can I start building my RAG workflow?
The first step involves collecting your data, cleaning it, chunking your data, and embedding your data in a lying smooth database. Next, integrate it with an LLM (such as GPT-4) through frameworks such as LangChain or LlamaIndex.