
What if the intelligence behind generative AI isn’t the model, however the facts it learns from? Generative AI creates content like textual content, photographs, and code by using studying styles from large datasets. The role of facts in generative AI is valuable, because it determines how correctly and creatively fashions perform.
High-best, numerous information permits higher education, satisfactory-tuning, and reliable outputs. Poor facts leads to biased or susceptible effects. Understanding what’s the position of data in generative AI facilitates agencies build more powerful and scalable AI systems that supply significant, applicable, and awesome results.
What is Generative AI?
Generative AI is a subset of synthetic intelligence that makes a speciality of developing new content as opposed to definitely reading current data. Unlike conventional AI models that classify or are expected to produce results, generative AI fashions generate absolutely new outputs primarily based on styles discovered throughout training.
These structures depend on superior strategies together with deep learning, neural networks, and natural language processing (NLP). They are skilled in handling huge datasets to recognize context, shape, and relationships within records.
Common examples consist of:
- Text technology equipment like ChatGPT that produces human-like responses
- Image technology fashions that create visuals from text prompts
- Code era systems that help developers in writing programs
These programs spotlight how generative AI transforms raw statistics into meaningful and innovative outputs.
Hire Skilled AI Prompt Engineers to refine your models and maximize generative AI performance.Get started today to achieve more accurate, efficient, and scalable AI results.
Why Data Is Important in Generative AI
Data is the spine of generative AI systems. These models do not own inherent expertise; alternatively, they examine entirely from the records they may be skilled on. The significance of facts in AI lies in its potential to form how models apprehend language, visuals, and styles.
During the education manner, AI fashions examine big amounts of data to discover relationships and systems. For instance, in herbal language processing, models research grammar, context, and semantics from textual content datasets. This procedure enables them to generate coherent and contextually applicable responses.
The function of schooling information in generative AI consists of:
- Teaching fashions the way to recognize styles
- Helping structures apprehend context and that means
- Enabling accurate and sensible output technology
Without enough and extraordinary information, generative AI fashions may also produce wrong, biased, or irrelevant consequences.
Types of Data Used in Generative AI
Structured Data
Structured data is prepared in a predefined format, consisting of tables, databases, or spreadsheets. It includes clearly described fields like numbers, categories, and labels. While generative AI is predicated greater heavily on unstructured facts, established information nonetheless performs a position in enhancing model accuracy and consistency.
Unstructured Data (Text, Images, Videos)
Unstructured data is the most critical type used in generative AI. It consists of:
- Text (articles, books, conversations)
- Images (pix, illustrations)
- Videos and audio
This sort of records lets in AI models to research complicated patterns, context, and relationships. For example, NLP models are educated on massive text corpora to comprehend language and generate meaningful responses.
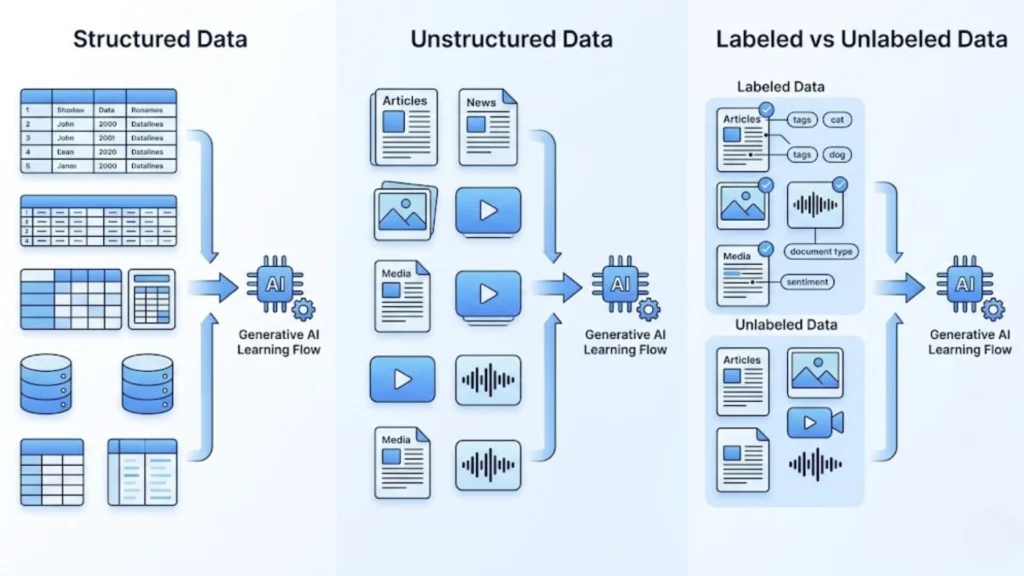
Labeled vs Unlabeled Data
- Labeled data consists of annotations or tags that help fashion study precise tasks (e.G., sentiment analysis).
- Unlabeled data do not have predefined labels and are frequently utilized in unsupervised learning.
Generative AI fashions often use an aggregate of both to enhance the knowledge of performance and performance.
Suggested Read: Generative AI Consulting: Transform Your Business Strategy in 2026
Role of Data in Training Generative AI Models
Data Collection
The first step in constructing a generative AI model is gathering huge volumes of relevant facts. This may additionally encompass textual content datasets, images, or area-specific information. The variety and length of the dataset without delay affect the version’s capabilities.
Data Preprocessing
Raw facts must be wiped clean and organized before schooling. This includes:
- Removing duplicates and errors
- Normalizing textual content and codecs
- Filtering inappropriate or harmful content material
Effective preprocessing guarantees that the version learns from correct and meaningful facts.
Model Training
During schooling, the AI model records tactics to study styles and relationships. Techniques, including deep learning and transformer fashions, are usually used. The version adjusts its internal parameters to minimize errors and improve the output greatly..
Fine-Tuning
After preliminary schooling, models are first-class-tuned using precise datasets to enhance performance for unique duties. For instance, a fashionable language model can be pleasant-tuned for customer support or technical writing.
Fine-tuning complements:
- Accuracy
- Context know-how
- Domain-particular know-how
How Data Quality Affects Generative AI
Accuracy
Highly exceptional statistics lead to accurate outputs. If the schooling statistics incorporate errors or inconsistencies, the model will reflect those problems in its responses.
Bias
Bias in statistics is a number one subject in generative AI. If the dataset consists of biased or unbalanced records, the model can also produce unfair or discriminatory outputs. Addressing bias calls for careful information preference and preprocessing.
Output Relevance
Relevant and diverse records ensure that the AI model generates meaningful and context-aware outputs. Poorly fine facts can result in inappropriate or nonsensical responses.
Data is awesome, immediately impacting the overall performance of AI systems, making it a vital thing in version development.
Transform your business with expert generative AI consulting tailored to your needs.
Partner with us to build scalable, efficient, and high-impact AI solutions.
Real-World Examples of Data in Generative AI
Text Generation
Generative AI fashions trained on big textual content datasets can create articles, summaries, and conversations. These structures rely heavily on NLP techniques to apprehend language patterns and context.
Bias in data is a primary concern in generative AI. If the dataset consists of biased or unbalanced data, the model may also produce unfair or discriminatory outputs. Addressing bias calls for careful data choice and preprocessing.
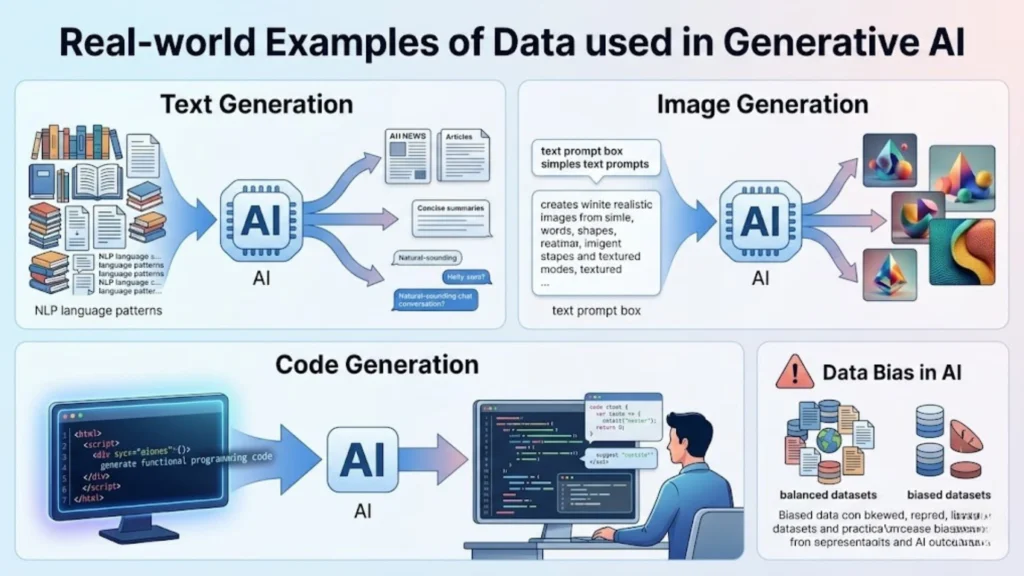
Image Generation
AI fashions educated on image datasets can generate realistic visuals based on textual content activations. These systems examine functions inclusive of shapes, colorings, and textures from big collections of photographs.
Code Generation
Generative AI equipment can assist developers by using producing code snippets and answers. These fashions are skilled on programming datasets, allowing them to recognize syntax and logic.
These examples exhibit how records enables generative AI to perform complex and innovative tasks across more than one domains.
Challenges of Using Data in Generative AI
Data Privacy
Using huge datasets often increases privacy issues, especially when private or touchy information is concerned. Ensuring compliance with records safety regulations is vital.
Bias Issues
Bias in schooling statistics can result in unfair results. Addressing this project requires careful dataset choice and ongoing tracking.
Large Data Requirements
Generative AI fashions require huge quantities of records to carry out efficaciously. Collecting and processing such information may be time-consuming and aid-intensive.
These annoying situations highlight the want for accountable facts manipulate in AI improvement.Bias in training facts can lead to unfair consequences. Addressing this venture requires cautious dataset selection and ongoing monitoring.
Schedule a 30-minute call to discuss your AI goals and explore the right strategy for your business. Connect with our experts to get clear, actionable insights tailored to your needs.
Conclusion
The role of data in generative AI is central to its success. From schooling to fine-tuning, information determines how efficiently AI fashions study, adapts, and generates outputs. High-quality, numerous, and well-processed records guarantee accuracy, relevance, and fairness in AI systems. As generative AI continues to evolve, the importance of statistics will most effectively increase, shaping the destiny of synthetic intelligence and its applications throughout industries.
Frequently Asked Questions
What is generative AI training data?
Generative AI training data refers to massive datasets used to train AI to fashion the way to generate content. This includes text corpora, image datasets, and code repositories that help fashion study styles and relationships.
How does statistical first-rate affect AI models?
High-quality data without delay affects AI overall performance. High-fine information improves accuracy and relevance, at the same time as negative-quality information can lead to biased, incorrect, or unreliable outputs.
Can generative AI work without facts?
No, generative AI cannot function without information. Data is important for education models, as it provides the styles and expertise required to generate outputs.
What are the demanding situations of statistics in generative AI?
The major challenges consist of record privacy worries, bias in datasets, and the need for massive volumes of outstanding statistics. These elements can have an effect on the model’s overall performance and reliability.