

The modern data-driven world is the place where businesses must make a critical decision.
Is it better to store the data in raw form in order to be able to flexibly use it, or is it preferable to structure the data initially to have fast access or analysis?
This option determines the correct option a Data lake vs data warehouse. Data lakes enable organizations to keep unstructured and semi-structured mass data which is useful later in the determination of observation, machine learning and advanced analytics.
Conversely, data warehouses are meant to handle structured information, which can be used to provide quick reporting, business intelligence, and insights to be used. Knowing the distinction between the two methodologies can assist firms in shaping a data strategy that would be able to provide scalability, speed, and analysis.
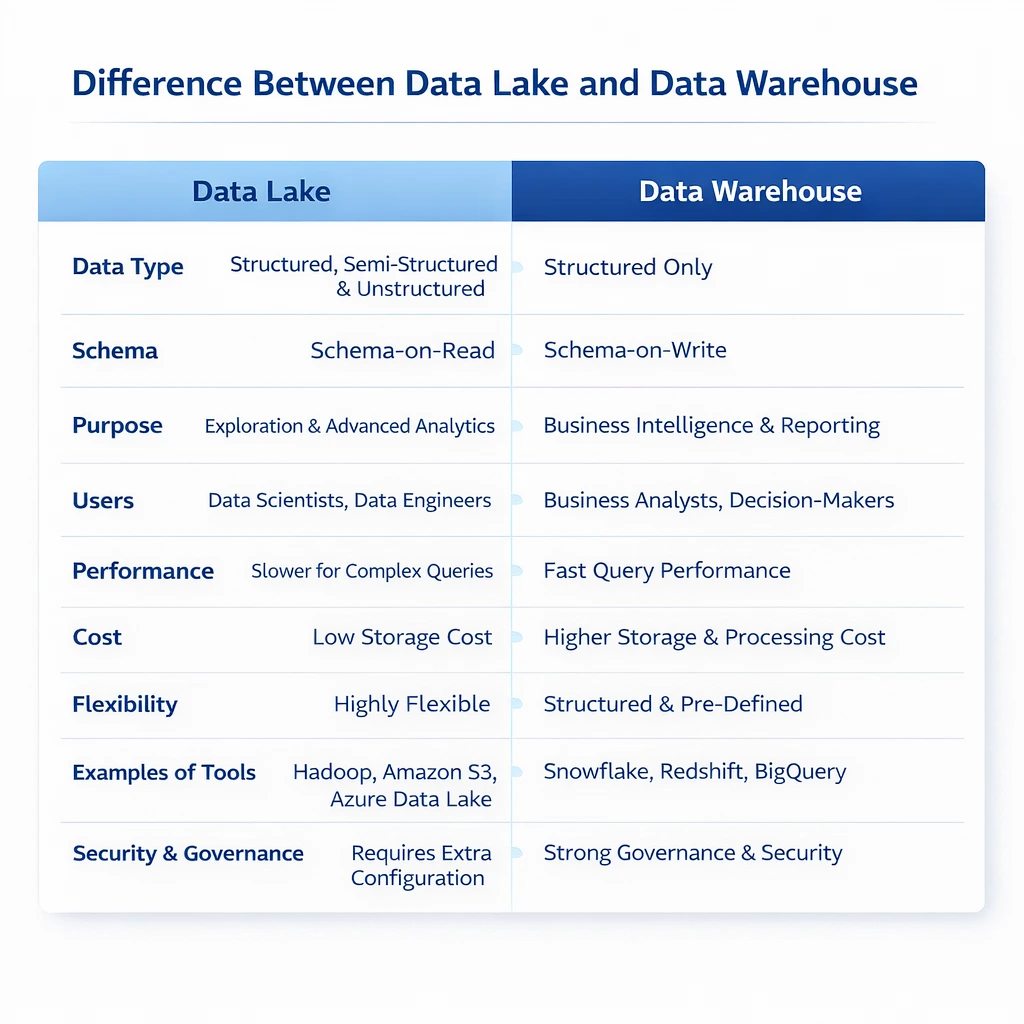
What Is a Data Lake?
A data lake is a centralized store where massive amounts of raw information are stored in their original form. This comprises structured data, semi-structured data, and unstructured data. The storage is followed by a subsequent structuring of the data that is accessed later when it is to be analyzed.
As an example, the e-commerce organization logs customer transactions, website clickstreams, product images, and customer reviews in a data lake. This raw data is then analyzed by data scientists to create recommendation engines and predictive models.
The following are some key benefits of using a Data Lake:
Scalability: Can support huge amounts of data.
Cost efficiency: The storage cost is less than in traditional warehouses.
Flexibility: Is compatible with various types of data and analytics loads.
Pros and Cons of a Data Lake
The following are the main advantages and disadvantages of a Data Lake to get to know its benefits and drawbacks in a short period:
| Pros | Cons |
| Stores organized and non-structured data | The possibility of ending up as a data swamp unless it is correctly governed. |
| Data exploration and experimentation | Slower response time of BI and reporting |
| Gathers AI and machine learning loads | Needs competent data engineers and data scientists |
| Schema-on-read offers flexibility in analyses | Firm data quality and security controls are needed. |
What Is a Data Warehouse?
A data warehouse is a centralized system that stores processed data from various sources of data in a structured format. It is meant to be fastly queried, reported, and business intelligent through the implementation of a known schema, and subsequent storage of the data.
As an example, a retail organization would be using a data warehouse to integrate sales, inventory, and customer data across systems into one system such that real-time dashboards and monthly performance reports are possible.
The following are some key benefits of using a Data Warehouse:
Fast analytical queries: Optimized high-performance SQL queries.
Single source of truth: Stable and dependable business reporting.
Good data quality: Validated and cleaned data.
Pros and Cons of a Data Warehouse
The following are the main advantages and disadvantages of a Data Warehouse in order to get a brief idea about the strengths and weaknesses:
| Pros | Cons |
| Analytics high query performance. | Increased storage/processing cost. |
| Systematic and properly structured data. | Weak support of non-structured data. |
| Effective data management and security. | Complicated data preparation (ETL) |
| BI and reporting tools Ideal. | Less flexible for exploratory analytics |
Key Differences Between Data Lake and Data Warehouse
The following are some of the main differences between a Data lake and a Data Warehouse to enable you grasp how each system retains, processes, and utilizes data in a short period of time.
Architecture of Data Lake and Data Warehouse
This is a straightforward description of the architectures of a Data Lake and a Data Warehouse, in terms of storing, processing, and delivering data to the modern business needs:
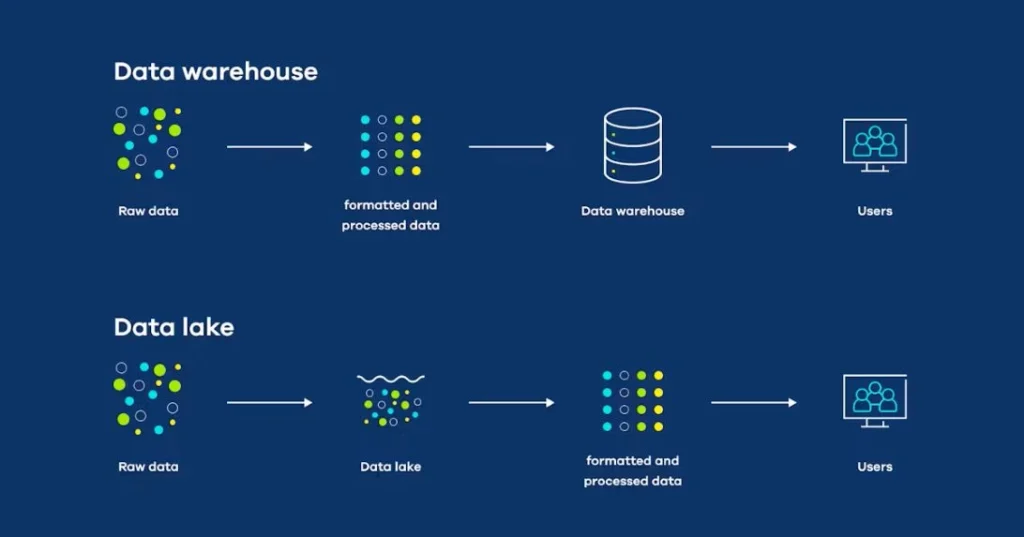
Data Lake Architecture
A data lake is created to deal with huge amounts of raw information in its original form. It begins using data sources (databases, IoT devices, system logs, CRM/ERP systems, social media feeds). The ingestion layer permits as-is data to pass through it in batches, real-time streams, or event-triggered feeds, which is highly flexible in the prospects of future analytics.
When data has been ingested, it is stored in a storage layer that supports structured, semi-structured, and unstructured data without a defined structure. Popular storage systems are HDFS, Amazon S3, and Azure Data Lake.
In order to ensure information is findable, a metadata and catalog layer ensures the maintenance of schema, lineage, and organization, by schema-on-read, implementing structure only when the data is read. The analytics/processing layer allows power analysis in support of AI, machine learning, predictive analytics, and exploratory research.
Lastly, governance and security layers provide data quality, compliance, and controlled access to the raw data, even though it is not an easy task due to the complexity of the diverse raw data, which is accessed by data scientists, engineers, and analysts.
Data Warehouse Architecture
Structured, processed data is constructed to form a data warehouse that can be used to provide fast and reliable business intelligence. It also starts with the database, ERP /CRM systems, and other operational systems data sources. In the ingestion layer, the data is processed by ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes to make it prepared and cleaned to be used in reporting.
This data is stored in relational tables in the storage layer, which makes querying and integration with analytics tools high-performance. They are Snowflake, Redshift, and BigQuery.
The metadata and catalog layer stores the schema definitions and provides a consistent structure through schema-on-write i.e., the data is arranged in advance before it gets into the warehouse. The analytics layer and processing are in place to support BI, KPI dashboards, and operational reporting, facilitating decision-makers to create insights in a short time frame.
The users are mainly business analysts and managers who need to have regular and structured information to make strategic choices, and the governance and security layer ensures that data quality, compliance, and access are strictly controlled.
Selecting the Appropriate Strategy For Your Company
The proper option of data strategy assists your business in realizing the potential of your data. A data lake can be explored flexibly and provides advanced analytics, whereas a data warehouse provides rapid, reliable reporting. Organizations are integrating the two in large numbers to have a balanced and powerful data architecture.
Reserve your spot for a free consultation on optimizing your data strategy.
1. When to Use a Data Lake
A data lake is the best for managing large amounts of varied data, structured, semi-structured, or unstructured. It is ideal when data scientists and engineers require raw data to perform an exploratory analysis, machine learning, predictive modeling, or an AI project. A data lake is used when you have the need to experiment and find revelations without prior schemas.
2. When to Use a Data Warehouse
A data warehouse is ideal for clean, structured, and processed data that is utilized in rapid query, reporting, and business intelligence dashboards. It is appropriate for business analysts and managers who need to have reliable, consistent data to use in making operational and strategic decisions. Use a data warehouse when speed of performance, control, and reporting are vital.
3. When to Use Both Together
A combination of the two solutions enables the organizations to have the best of both worlds. Handling Data lake Raw and varied information is stored in a data lake to be explored, analyzed through AI and advanced analytics. Structured datasets are then transferred to a data warehouse in order to create fast reporting and decision-making. Such a hybrid solution guarantees the flexibility of the innovation process but does not compromise business operations in terms of reliability and speed, as well as governance.
Final Thoughts
Understanding the differences between a data lake and a data warehouse is essential for managing your enterprise data effectively. Both systems can be used individually or together to support analytics, reporting, and decision-making.
Explore how you can Hire AI Engineers to optimize your data strategy.
Frequently Asked Questions (FAQs)
Is Snowflake a Data Lake or a Data Warehouse?
Snowflake is a cloud-based data warehouse designed for structured and semi-structured data. It helps to quickly generate analytics, reporting, and business intelligence; and therefore is suitable in cases where an organization requires high performance and dependable insights.
Is a Data Warehouse Structured or Unstructured?
A data warehouse is a database that is made up of structured and processed information in the form of relational tables. It is also optimized with BI, dashboards, and reporting, which will guarantee consistent and accurate business knowledge.
What is the Difference Between a Data Lake and a Data Lakehouse?
A data lakehouse is a combination of a data lake and a data warehouse in the sense that it offers the dynamism of a data lake and the performance of a data warehouse. It enables the storage of raw data to be explored, as well as providing a quicker analytics and reporting system in a single platform.
What Are the 5 Types of Data Warehouse Architectures?
Single-Tier: Stores, processes, and presents the data; not very complex but less scalable.
Two-Tier: Storing and reporting are independent; more performance, but could experience bottlenecks.
Three-Tier: The most common; consists of data sources, ETL/storage, and reporting/BI tools.
Cloud-Based: It employs such platforms as Snowflake, Redshift, or BigQuery; it is scalable and cost-effective.
Data Lakehouse: Raw data and high-performance structured analytics.
Can a Business Use Both a Data Lake and a Data Warehouse?
Yes. A lot of organizations keep raw and heterogeneous data in a data lake to be accessed by AI and analytics, and transfer refined and structured data to a warehouse to be able to report swiftly and to do BI. This is a flexible and reliable approach in a hybrid form.